

Kunstig intelligens, maskinlæring, datadeling og –lagring. Slik kan digitalisering effektivisere oljebransjen.
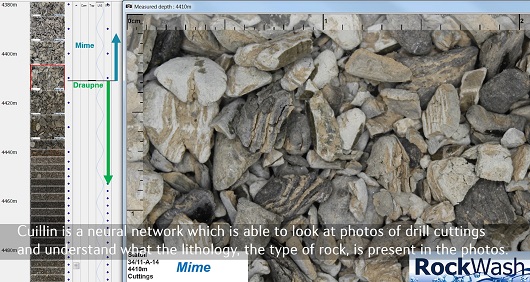 Equinors Cuillin-prosjekt trener opp maskiner til å analysere og klassifisere borkaks. Bilde hentet fra video på Equinors nettsider
Equinors Cuillin-prosjekt trener opp maskiner til å analysere og klassifisere borkaks. Bilde hentet fra video på Equinors nettsider
Konsulentfirmaet McKinsey & Company har anslått at besparelsespotensialet på norsk sokkel kan være 30 – 40 milliarder kroner per år ved digitalisering.
Teknisk sett har petroleumsbransjen i Norge vært digital i årevis. Men industrien opplever nå store og raske forandringer i det som blir kalt en ny digitaliseringsbølge.
LES OGSÅ: Den digitale oljebølgen
Årsaken er tilgang på nært sagt uendelig og billig prosesseringskraft og lagringsmuligheter, bedre programvareløsninger og fremskritt innen kunstig intelligens og maskinlæring.
Og under DigEx-konferansen på Gardermoen sent i januar ble de fremmøtte servert hele 35 foredrag av representanter fra operatører og service-, konsulent- og IT-selskaper som viste hvordan ny bruk av data forbedrer bransjen med hensyn på tidsbruk, kostnader og kunnskapservervelse og –deling.
Kort fortalt er maskinlæring algoritmer som lar datamaskiner lære fra og utvikle adferd basert på data. Jo mer data de får, desto flinkere blir de til å gjenkjenne mønstre og gjøre beslutninger.
Kunstig intelligens er teknikker som lar datamaskiner etterlikne menneskelig intelligens. Maskinlæring er primært datadrevet, mens kunstig intelligens bygges opp ved en kombinasjon av datamating og grunnleggende teorier.
Borkaks, huskyhunder og ulver
 David Wade, Equinor. Foto: Ronny Setså
David Wade, Equinor. Foto: Ronny Setså
David Wade fra Equinor presenterte et prosjekt som har undersøkt hvordan maskiner kan trenes opp til å korrekt tolke borkaks (cuttings) ved hjelp av bildeanalyse i såkalte nevrale nettverk.
Et interaktivt eksempel på hvordan nevrale nettverk virker finner du her.
Wade hevdet borkaks tradisjonelt har vært en delvis uutnyttet kilde til informasjon om undergrunnen fordi det i stor grad kun har vært geologen på boreplattformen som har studert dem. Ved å digitalisere bildene, kan hvem som helst studere de verdifulle bitene av stein. I tillegg kan maskiner mye raskere enn mennesker analysere og klassifisere dem.
– Vi har så langt oppnådd en overraskende høy nøyaktighet på bildeanalysene ved hjelp av maskinlæring, sa Wade, og refererte til en nøyaktighetsgrad (såkalt F1-score) på ca. 80 prosent.
Én av utfordringene ved å bruke nevrale nettverk for å analysere data, er såkalt «black box»-problematikken som går ut på at data går inn og data kommer ut uten at en har fått innblikk i prosessen bak.
Det er ifølge Wade helt nødvendig å kunne «kikke maskinen over skulderen» og vite om den tenker riktig. Som eksempel trakk han frem en test der en maskin skulle skille huskyhunder fra ulver.
– I de tilfeller der maskinen analyserte feil, viste det seg at den hadde skilt mellom dyrene basert på hvorvidt det var snø i bildet i stedet for å fokusere på selve dyret, sa Wade.
Sporer forkastninger og horisonter
To av foredragsholderne, Diderich Buch (Bluware) og James Lowell (Geoteric) viste hvordan en ved hjelp av maskinlæring automatisk kan spore forkastninger i seismiske data.
 James Lowell, Geoteric. Foto: Ronny Setså
James Lowell, Geoteric. Foto: Ronny Setså
Dette kan redusere tiden som brukes på seismisk tolkning betraktelig, men ettersom presisjonen til maskinene er godt under 100 prosent, vil det fortsatt være behov for et menneskelig blikk og tenkning.
Det samme kan sies om automatisk gjenkjenning av seismiske horisonter. Én av foredragsholderne som tok for seg dette temaet var Aina Bugge, stipendiat tilknyttet Universitetet i Oslo, Lundin Norge og Kalkulo. Hun viste eksempler på hvordan de har trent maskiner til å tolke 3D seismikk og hvilke statistiske metoder som kan benyttes for formålet.
Datadeling
Den kanskje mest utslagsgivende faktoren innen digitalisering er datahåndtering og –deling. Flere av foredragsholderne fremholdt viktigheten av nye og bedre løsninger for å samle flere tiår med data i enkle, brukervennlige – og digitale – databaser.
Et eksempel å trekke frem er Isabel von Steinaeckers (Cegal) foredrag om hvordan Cegal hjalp oljeselskapet OKEA å organisere dataene sine etter at de kjøpte store andeler i Draugenfeltet fra Norske Shell.
I forbindelse med kjøpet fikk OKEA overlevert store mengder data som kom i nært sagt alle former; seismiske data, kjernedata, eldre data på teip, nye og gamle rapporter, kjerneprøver, væskeprøver, fotografier og DVDer, for å nevne noe.
Cegal bidro med å digitalisere og tilgjengeliggjøre alle dataene på en plattform, noe som ifølge von Steinaecker sparer de ansatte for mye tid de ellers ville brukt på å jobbe med komplekse data fordelt på ulike plattformer og fysiske lokaliteter.
Seniorforsker i SINTEF Industri Ane Lothe fremholdt også viktigheten av datadeling og poengterte at en åpen plattform for data- og programvaredeling blant forskningsmiljøene i Norge er noe som fortsatt mangler.
Sammen med Universitetet i Oslo, NTNU, Norges geologiske undersøkelse og Norsk regnesentral har SINTEF sendt inn en søknad til Forskningsrådet om midler til utvikling av «Norwegian Digital Subsurface Lab». Laben skal kunne la forskningsmiljøene jobbe med bedre forståelse av undergrunnen og reservoarer fra pore- til bassengskala.
 Ane Lothe, SINTEF Industri. Foto: Ronny Setså
Ane Lothe, SINTEF Industri. Foto: Ronny Setså
Andre artikler om digitalisering:
Den digitale oljebølgen
Digital satsing for norsk sokkel
Ung, lovende, analytisk og lærevillig
Kunstig intelligens i kartlegging
")